
Hoy en día, existen numerosos motores de búsqueda disponibles en internet que utilizamos diariamente para hacer miles de consultas y es realmente abrumadora la gran cantidad de información que estos nos proporcionan.
Buscadores como Google, Yahoo, Bing, Baidu, etc son ejemplo de ello, cada uno con sus propias capacidades y características, pero, actualmente hay un rey en cuanto a motores de búsqueda se refiere y ese es Google, el buscador más popular y utilizado actualmente en todo el mundo.
Pero, ahora que ya hemos puesto en pie su importancia, ¿Realmente te has preguntado cómo funciona un buscador para dar respuesta a las preguntas de los usuarios? ¿Cómo es posible que Google encuentre lo que estás buscando con tanta velocidad y precisión?
Para entenderlo, nos centraremos en explicarte cómo funciona el buscador Google en detalle.
¿Cómo funcionan los motores de búsqueda?
Todo comienza cuando introducimos una palabra o frase en el buscador, que, tras darle a buscar, Google nos muestra millones de páginas web al momento que contienen o pueden contener información para dar respuesta a nuestra consulta.
El principal objetivo de Google es ofrecerle al usuario la información que este necesita, es decir, información relevante, y para ello selecciona que resultados mostrarte primero y los ordena según la prioridad que crea adecuada para tu búsqueda.
El funcionamiento de buscador Google puede dividirse en tres fases: Rastreo, indexación y devolución de resultados de búsqueda.
1. Rastreo en Google
El primer paso que lleva a cabo el buscador es el rastreo de los millones de páginas web que hay en internet ya que continuamente se están creando nuevas páginas o se actualizan las que ya están creadas.
Para ello, lo primero que debe hacer Google es averiguar que páginas hay dentro de una web, pero ¿Cómo lo hace?
Este rastreo comienza a partir de una lista de direcciones web que Google ha obtenido de anteriores rastreos o también de los archivos Sitemaps que han sido elaborados por los propietarios de los sitios web. Un sitemap es un archivo XML que contiene una lista con todas las URL que queremos que indexe Google y con este listado le comunicas a Google las actualizaciones que has hecho en tu web, las páginas que quieres que indexe y con qué frecuencia se actualiza tu web.
Para crawlear o rastrear estas webs Google se ayuda de los Googlebot o llamado de forma más coloquial las “arañas de Google” o “Crawler de Google” que entran, leen el código fuente de tu página y analizan el contenido para ver que ha cambiado con respecto a versiones anteriores o van siguiendo los enlaces que contienen estas páginas para descubrir nuevas.
Toda esta información se lleva al servidor para que se procese, clasifique y pondere las optimizaciones seo que tiene esa página web. Posteriormente hablaremos de ello en la fase de indexación.
Por otro lado, así como hay páginas que quieres que Google rastree, hay otras muchas que deseas que no se visiten, por ejemplo, aquellas páginas que son irrelevantes para el negocio como las páginas legales o bloquear partes de la web que generan contenido duplicado por ejemplo las categorías del sitio web, y para ello debes decirle a Google que no te las rastree y esto se hace con un archivo robots.txt. Estos archivos robots.txt también sirven para gestionar el tráfico de los rastreadores al sitio web.
Todo este proceso de rastreo tiene un tiempo finito, es lo que se conoce como Crawl Budget, es decir, que tienes un número de milisegundos asignado para que los bots paseen por tu web para rastrearla. Google asigna según la autoridad, accesibilidad, velocidad y calidad más o menos tiempo de rastreo, y este Crawl Budget puede optimizarse.

Problemas de rastreo
Puede haber casos que las arañas de Google no puedan rastrear bien la página web. Los problemas pueden ser los siguientes:
- No incluir URLs en el Sitemap
- Ser bloqueado por robots.txt
- Tener demasiados niveles de profundidad en la página web.
- Enlazar con enlaces no HTML
- Abusar de Java Scrip en el código
- No enlazar (Que haya URLs huérfanas)
- Tiempos de carga excesivos
2. Indexación en Google
Tras recibir toda la información que los rastreadores obtienen de las páginas web, el siguiente paso es procesar y ordenar todos esos datos.
Si nos vamos a la RAE, “indexar es registrar ordenadamente datos en informaciones, para elaborar su índice” que, extrapolado al entorno digital, el índice más claro que tenemos son las SERP (Search Engine Results Page) de Google.
La indexación de Google no es más que esa clasificación del contenido en función de la información que contenga para añadirla a la gran base de datos de Google.
El objetivo de esto es que, tras una búsqueda del usuario, Google solo debe acudir a la parte de su índice donde se encuentra clasificada esa información que está buscando el usuario para mostrársela y posicionarla por orden de relevancia para el usuario.
Existen varias formas de comprobar si una página ha sido indexada:
- Google Search Console: Se debe entrar en la sección de rastreo de la herramienta → Inspección de URLs → Introducir la dirección que se quiere comprobar.
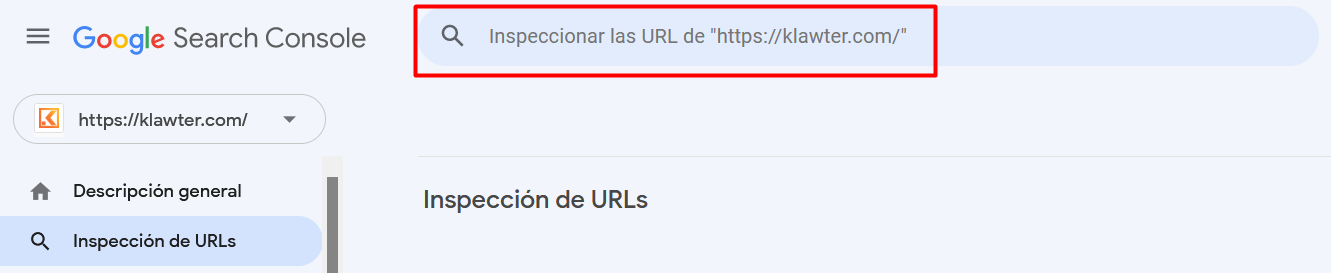 Cuando Google Search Console haya acabado el análisis, Si la URL no estaba indexada salta el mensaje “Solicitar indexación”.
Cuando Google Search Console haya acabado el análisis, Si la URL no estaba indexada salta el mensaje “Solicitar indexación”.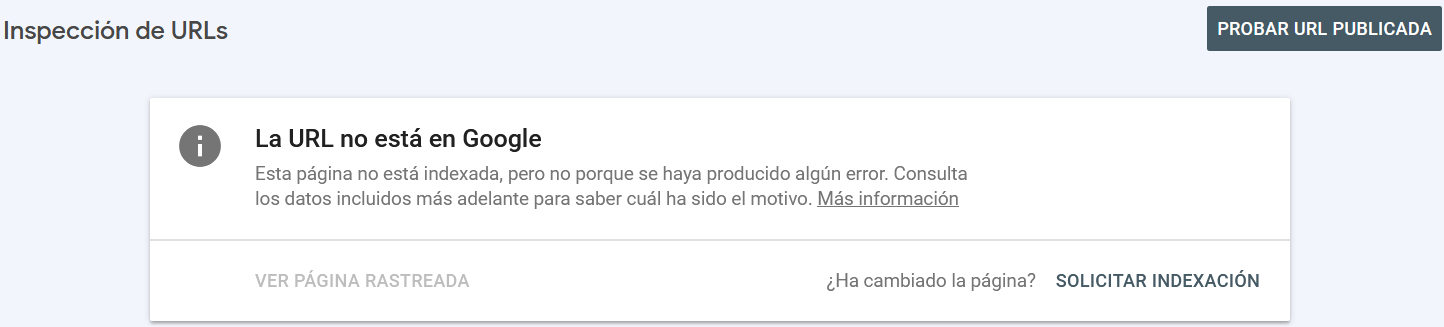
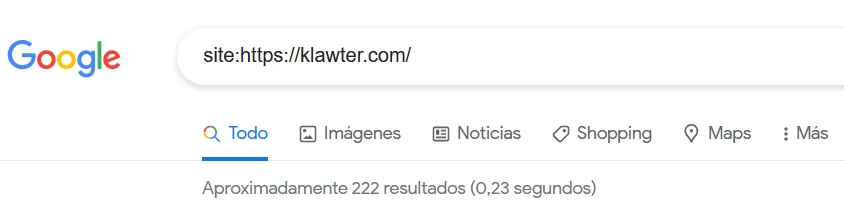
- Haciendo una comprobación manual en Google añadiendo en el buscador “site:” seguido de la URL del sitio web y si aparece como resultado de búsqueda es que ya está indexada. En el propio buscador te dice cuantas URLs de tu página web se encuentran indexadas.
- Analizar tu web con alguna herramienta SEO como por ejemplo Screaming Frog y ver que URLs están indexadas.
¿Qué hacer para conseguir que Google nos indexe?
- Configurar el Google search console en tu página web.
- Crear un sitemap.
- Crear los archivos robots txt.
- Estudio de palabras clave.
- Añade contenido de calidad frecuentemente.
- Crea un buen enlazado interno y extermino.
- Vigila que no existan URL rotas.
3. Devolución de resultados de búsqueda
Tras la fase de rastreo e indexación, llega el momento donde el usuario hace una consulta en el buscador, y es que, ¿Cómo selecciona el buscador los contenidos más relevantes para ti?
Para una intención de búsqueda concreta del usuario, el algoritmo de Google identifica en su índice que es lo que quieres encontrar y cuál sería la respuesta más relevante a tu pregunta. En función de lo que tu estés buscando y gracias a técnicas SEO implementadas en las páginas webs determina el orden en el que vas a ver el listado de páginas, atendiendo a diferentes factores como la relevancia de la página web y la autoridad.
Clasificación de URLs según su indexación y rastreabilidad
Muchas veces se confunde el rastreo y la indexación, y es que son dos procesos totalmente distintos, porque como ya indicábamos antes, el rastreo es esa búsqueda de contenido y la indexación su clasificación en el índice de Google.
Pero ¿Si una URL no se puede rastrear tampoco se puede indexar?
Esto da pie a confusión, y es que, aunque una URL puede no ser rastreada por el boot de Google si puede ser indexada al mismo tiempo. Hay muchos casos que pueden darse en la URLs de nuestro sitio web, entre ellas:
- URLs rastreables e indexables: Son aquellas URLs en las que Google puede acceder y ver su contenido y además es indexada por este motor de búsqueda. Pero esto no significa que al ser rastreable siempre sea indexada, ya que si Google no la considera relevante para la búsqueda puede que no la indexe.
- Rastreables y no indexables: Estas URLs son aquellas en las que Google puede acceder a ella y rastrear su contenido pero se le ha indicado que no queremos que la indexe en los resultados de búsqueda.
- No rastreables e indexables: Son aquellas URLs que no queremos que Google acceda y no podrán leer los meta-robots, pero si que pueden ser indexadas a través de otros contenidos (Enlaces externos, sitemap, etc). Normalmente estas URLs están definidas con el robot.txt para que no se rastree.
- No rastreable y no indexables: URLs definidas como <noindex> y además con el acceso bloqueado a los crawlers de Google para que no puedan ser ni rastreadas ni indexadas.
¿Por qué es importante que Google indexe tu página web?
Como hemos comentado anteriormente, no estar indexado es no aparecer en los resultados de búsqueda y por lo tanto no existes para Google y en consecuencia tampoco existes para los usuarios. Por lo que, si tienes una página web y no está indexada, directamente no existes.
Al no estar indexada la web no obtienes ningún beneficio, pero cuando logras una indexación correcta, esto se transforma en un aumento del tráfico a tu pagina web y a mejorar tu posicionamiento.
Por ello es también muy importante que aparte de que el contenido esté bien indexado, este sea de calidad y tenga un buen posicionamiento SEO, pues hay una relación directamente proporcional entre la mejora del posicionamiento orgánico y el aumento al tráfico web. Google asignará a tu página web un posicionamiento en la SERP que variará dependiendo de nuestro trabajo SEO realizado en la página, tanto el SEO on Page como el SEO off Page.
Ahora que entiendes cómo funciona el buscador de Google, sabes la importancia del rastreo y la indexación tu página web para aparecer en Google. Si tienes una web y no está indexada, directamente no existe tu página web.
En Klawter somos expertos en posicionamiento SEO y podemos conseguir que tu web se muestre en los resultados de búsqueda de manera óptima. No dudes en pedirnos presupuesto.







